Create and materialize partitioned assets
Partitions are a core abstraction in Dagster that allow you to manage large datasets, process incremental updates, and improve pipeline performance. You can partition assets the following ways:
- Time-based: Split data by time periods (e.g., daily, monthly)
- Category-based: Divide by known categories (e.g., country, product type)
- Two-dimensional: Combine two partition types (e.g., country + date)
- Dynamic: Create partitions based on runtime conditions
In this step, you will create a time-based asset partitioned by month.
1. Create a time-based partitioned asset
There are many ways to partition an asset. When an asset is partitioned, it is still represented as a single asset in the asset graph, but is defined by the number of underlying partitions. We will create a new asset that calculates the monthly performance for each sales rep. Before we define the asset, however, we must define the partition definition.
Dagster natively supports partitioning assets by datetime groups. To create the monthly partition, copy the following code below the missing_dimension_check asset check in the assets.py file:
monthly_partition = dg.MonthlyPartitionsDefinition(start_date="2018-01-01")
This partition definition can now be used in an asset:
@dg.asset(
deps=["stg_orders"],
kinds={"duckdb"},
partitions_def=monthly_partition,
automation_condition=dg.AutomationCondition.eager(),
description="Monthly sales performance",
)
def monthly_orders(context: dg.AssetExecutionContext, duckdb: DuckDBResource):
partition_date_str = context.partition_key
month_to_fetch = partition_date_str[:-3]
table_name = "jaffle_platform.main.monthly_orders"
with duckdb.get_connection() as conn:
conn.execute(
f"""
create table if not exists {table_name} (
partition_date varchar,
status varchar,
order_num double
);
delete from {table_name} where partition_date = '{month_to_fetch}';
insert into {table_name}
select
'{month_to_fetch}' as partition_date,
status,
count(*) as order_num
from jaffle_platform.main.stg_orders
where strftime(order_date, '%Y-%m') = '{month_to_fetch}'
group by '{month_to_fetch}', status;
"""
)
preview_query = (
f"select * from {table_name} where partition_date = '{month_to_fetch}';"
)
preview_df = conn.execute(preview_query).fetchdf()
row_count = conn.execute(
f"""
select count(*)
from {table_name}
where partition_date = '{month_to_fetch}'
"""
).fetchone()
count = row_count[0] if row_count else 0
return dg.MaterializeResult(
metadata={
"row_count": dg.MetadataValue.int(count),
"preview": dg.MetadataValue.md(preview_df.to_markdown(index=False)),
}
)
Partitions are accessed through the context object, which is passed to each asset during execution and provides runtime information. When running an asset for a specific partition date, we can reference that value using context.partition_key. The rest of the asset implementation should resemble the other assets we've defined. In this case, we are creating a new table, monthly_orders, using data from the stg_orders dbt model. We first delete any existing data for the current partition, then insert new data for that partition. This ensures that our pipeline is idempotent, allowing us to re-execute the same partition without duplicating data.
Do not worry about the automation_condition in the dg.asset decorator for now. This is not necessary, but will make more sense when we discuss automation later.
2. Materialize partitioned assets
To materialize these assets:
-
Navigate to the assets page.
-
Reload definitions.
-
Select the
monthly_sales_performanceasset, then Materialize selected.When materializing a partitioned asset, you will need to select which partitions to execute. Because our partition has a start date (
"2018-01-01") and no end date, there will be partitions for every month starting from 2018. Only select partitions for the first four months of 2018:[2018-01-01...2018-05-01] -
Launch a backfill. After the execution is finished, you can see the subset of total partitions that have executed:
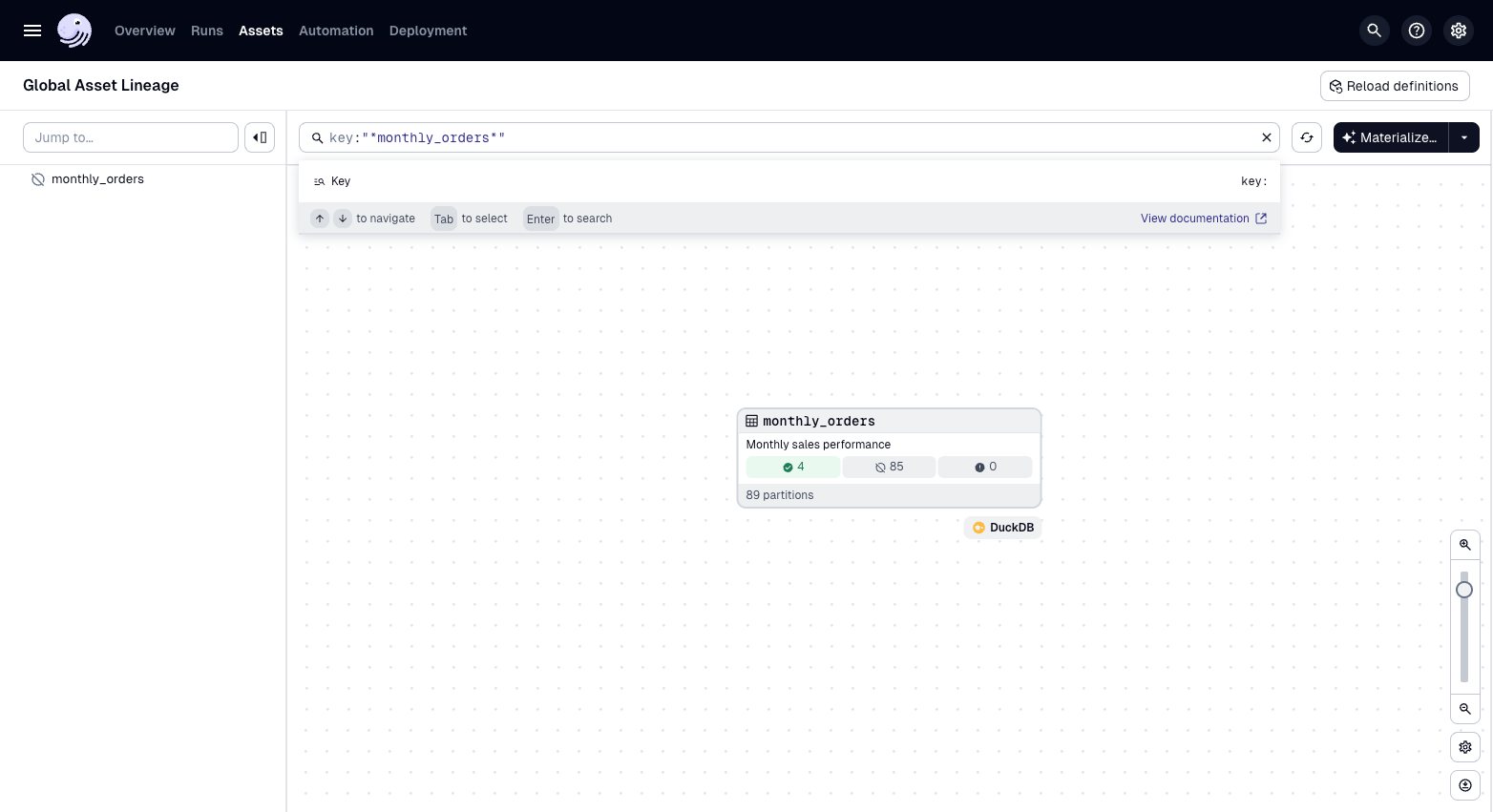
Summary
Partitions provide operational flexibility by allowing you to launch runs that materialize only a subset of your data without affecting the rest, and support backfilling capabilities to reprocess historical data for specific time periods or categories. As you are developing assets, consider where partitions might be helpful.
Next steps
Now that we have the main assets in our ETL pipeline, it's time to automate our pipeline.