Ensure data quality with asset checks
Data quality is critical in data pipelines. Inspecting individual assets ensures that data quality issues are caught before they affect the entire pipeline. In this step, you will:
- Define an asset check
- Execute that asset check in the UI
1. Define an asset check
In Dagster, you can define asset checks the same way you define assets. Asset checks run when an asset is materialized and ensure that certain criteria are met based on logic defined within the asset check.
You can place an asset check in the assets.py file alongside the asset it validates. Defining an asset check is similar to creating an asset. We define a function and decorate it with @dg.asset_check. Within the asset check, we need to set the asset parameter, which will determine which asset the asset check runs against.
In our case, we'll create an asset check on the raw_customers asset. We want to make sure that the underlying DuckDB table in that asset does not have any nulls in the id column:
@dg.asset_check(
asset=raw_customers,
description="Check if there are any null customer_ids in the joined data",
)
def missing_dimension_check(duckdb: DuckDBResource) -> dg.AssetCheckResult:
table_name = "jaffle_platform.main.raw_customers"
with duckdb.get_connection() as conn:
query_result = conn.execute(
f"""
select count(*)
from {table_name}
where id is null
"""
).fetchone()
count = query_result[0] if query_result else 0
return dg.AssetCheckResult(
passed=count == 0, metadata={"customer_id is null": count}
)
Our asset check queries the table directly to determine if the data is valid. Based on the result of the query, we either set the AssetCheckResult to pass or fail.
The asset check is using the same DuckDBResource resource we defined for the asset. Resources can be shared across all objects in Dagster.
Run dg dev (if it is not already running) and go to the Dagster UI http://127.0.0.1:3000. You should now see that an asset check is associated with the joined_data asset:
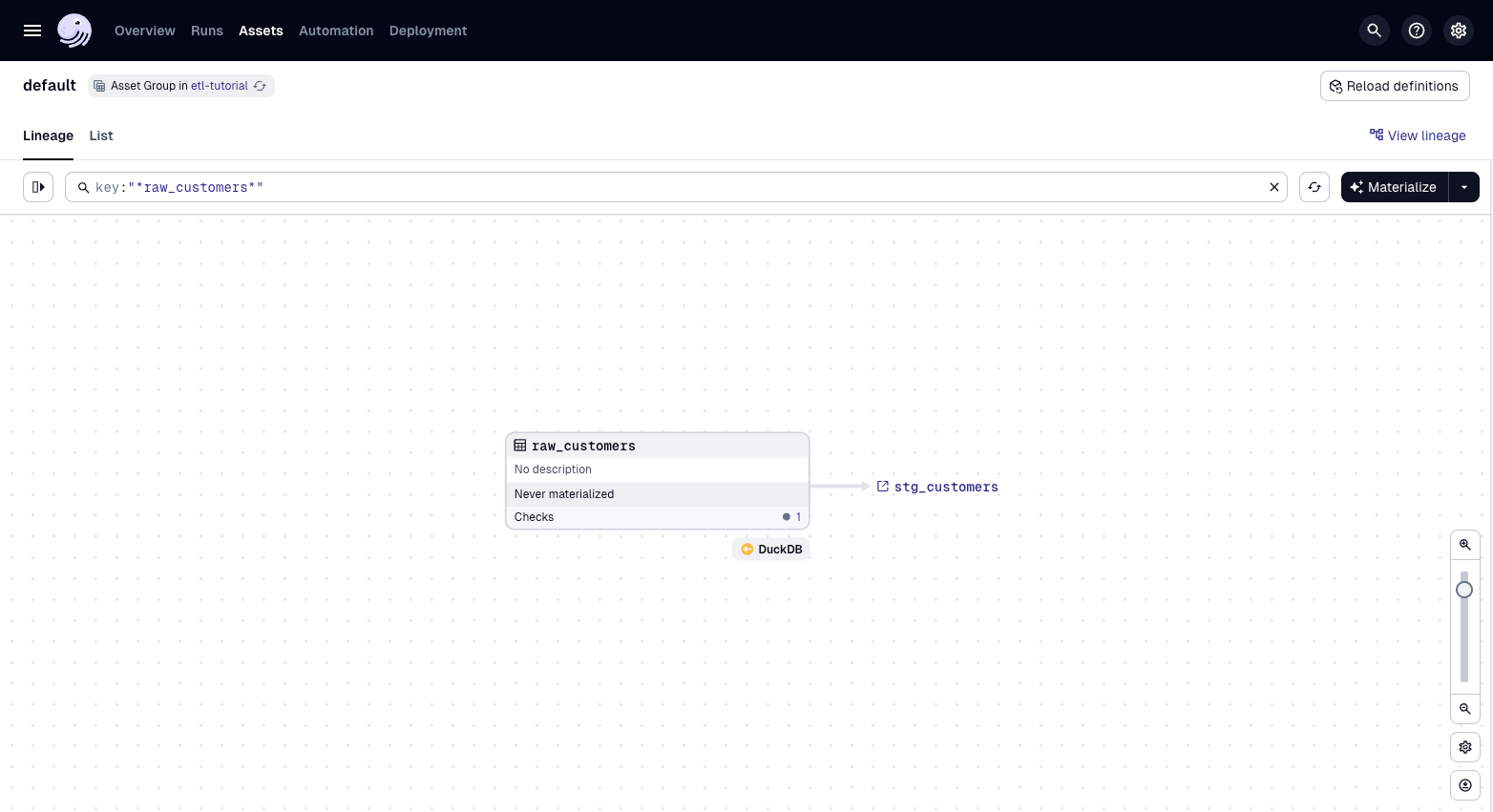
Asset checks will run when an asset is materialized, but asset checks can also be executed manually in the UI:
-
Reload your Definitions.
-
Navigate to the Asset Details page for the
raw_customersasset. -
Select the "Checks" tab.
-
Click the Execute button (assuming the asset has already executed) for
missing_dimension_check.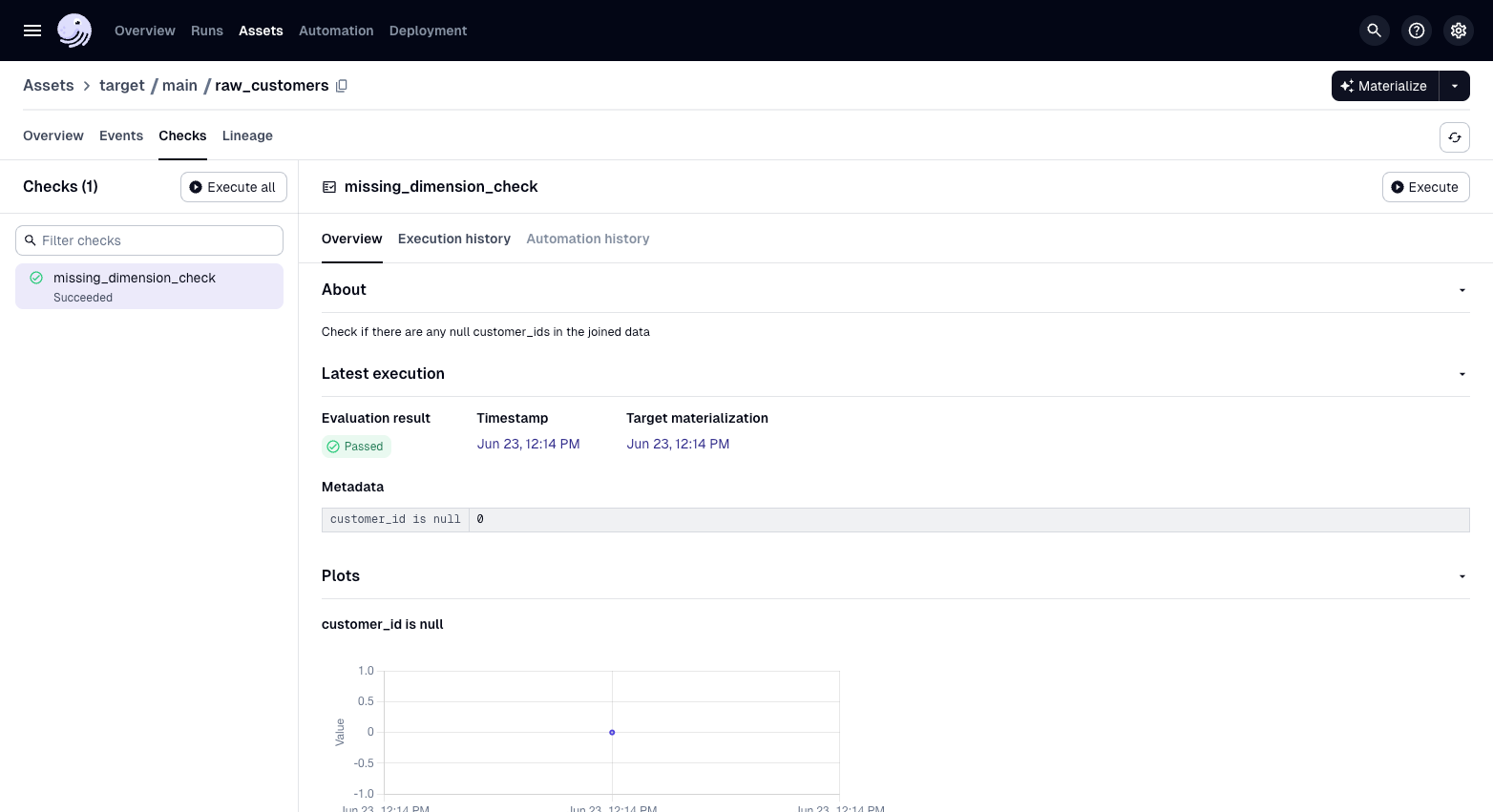
Summary
The structure of the etl_tutorial module has remained the same:
src
└── etl_tutorial
├── __init__.py
├── definitions.py
└── defs
├── __init__.py
├── assets.py
├── resources.py
└── transform
└── defs.yaml
But there are now data checks on the assets we have created to help ensure the quality of the data in our pipeline.
Next steps
- Continue this tutorial with creating and materializing partitioned assets